本文共 9865 字,大约阅读时间需要 32 分钟。
【爬虫】4入门Python网络爬虫
我们已经学习了:
- 使用Request自动爬取HTML页面,自动网络请求提交
- 使用robot.txt,这是网络爬虫排除标准
接下来学习学习Beautiful Soup,来解析HTML页面
网络爬虫之提取
1、Beautiful Soup库入门
(1)Beautiful Soup库的安装
https://www.crummy.com/software/BeautifulSoup/
发现Anaconda没有自带这个库,我们安装一下。管理员身份运行命令行,输入:pip install beautifulsoup4
结果:
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simpleRequirement already satisfied: beautifulsoup4 in e:\programdata\anaconda3\lib\site-packages (4.9.1)Requirement already satisfied: soupsieve>1.2 in e:\programdata\anaconda3\lib\site-packages (from beautifulsoup4) (2.0.1)
结果说已经有这个库了?噢,我用的Python3.8的环境,换成Anaconda就好了。
那安装好之后测试一下,演示HTML页面地址为:
https://python123.io/ws/demo.html同样,F12看一看页面源代码,也可以使用之前讲个Requests库,这是HTML 5.0格式代码:
This is a python demo page The demo python introduces several python courses.
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:Basic Python and Advanced Python.
下面利用Beautiful Soup库看看效果,代码如下:
import requestsfrom bs4 import BeautifulSoupr = requests.get('https://python123.io/ws/demo.html')demo = r.textsoup = BeautifulSoup(demo, 'html.parser')print(soup.prettify()) 结果:
This is a python demo page The demo python introduces several python courses.
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: Basic Python and Advanced Python .
Process finished with exit code 0
可以发现格式和原来的一致了,针不戳

(2)Beautiful Soup库的基本元素
Beautiful Soup库是解析、遍历、维护“标签树”的功能库

..
: 标签Tag
名称Name——成对出现
属性Attributes——0个或多个Beautiful Soup库,也叫beautifulsoup4 或bs4 约定引用方式如下,即主要是用BeautifulSoup类
from bs4 import BeautifulSoupimport bs4
标签树对应着BeautifulSoup类,BeautifulSoup对应一个HTML/XML文档的全部内容
Beautiful Soup库解析器如下:
soup=BeautifulSoup('data','html.parser') 

a.Tag标签
还是对之前的例子,执行以下代码:
import requestsfrom bs4 import BeautifulSoupurl = 'http://python123.io/ws/demo.html'r = requests.get(url)soup = BeautifulSoup(r.text, 'html.parser')print(soup.title) # This is Tagprint(soup.a) # This is also a Tag
结果:
This is a python demo page Basic Python
任何存在于HTML语法中的标签都可以用soup.访问获得 当HTML文档中存在多个相同对应内容时,soup.返回第一个
b.Name
还是对之前的例子,执行以下代码:
import requestsfrom bs4 import BeautifulSoupurl = 'http://python123.io/ws/demo.html'r = requests.get(url)soup = BeautifulSoup(r.text, 'html.parser')print(soup.a.name)print(soup.a.parent.name)print(soup.a.parent.parent.name)
结果:
apbody
每个都有自己的名字,通过.name获取,字符串类型
c.Attributes(属性)
对之前的例子,执行以下代码:
import requestsfrom bs4 import BeautifulSoupurl = 'http://python123.io/ws/demo.html'r = requests.get(url)soup = BeautifulSoup(r.text, 'html.parser')tag = soup.aprint(tag.attrs)print(tag.attrs['class'])print(tag.attrs['href'])print(type(tag.attrs))print(type(tag))
结果如下:
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}['py1']http://www.icourse163.org/course/BIT-268001 Process finished with exit code 0 一个<tag>可以有0或多个属性,字典类型
d.NavigableString
import requestsfrom bs4 import BeautifulSoupurl = 'http://python123.io/ws/demo.html'r = requests.get(url)soup = BeautifulSoup(r.text, 'html.parser')tag = soup.aprint(tag)print(tag.string)print(soup.p)print(soup.p.string)print(type(soup.p.string))
结果如下:
Basic PythonBasic PythonThe demo python introduces several python courses.
The demo python introduces several python courses.
NavigableString可以跨越多个层次
e.Comment
from bs4 import BeautifulSoupsoup = BeautifulSoup(" This is not a comment
", 'html.parser')print(soup.prettify())print(soup.b.string)print(soup.comment) # 注意一下print(soup.p.string)print(type(soup.b.string))print(type(soup.p.string)) 结果如下:
This is not a comment
This is a commentNoneThis is not a comment
Comment是一种特殊类型
可以总结一下,HTML就由以上五种元素构成。

(3)基于bs4库的HTML内容遍历方法
再次回忆一下之前的HTML基本格式:
<>…</>构成了所属关系,形成了标签的树形结构,如下所示: 

a.标签树的下行遍历

import requestsfrom bs4 import BeautifulSoupurl = 'http://python123.io/ws/demo.html'demo = requests.get(url)soup = BeautifulSoup(demo.text, 'html.parser')print(soup.head)print(soup.head.contents)print(soup.body.contents)print(len(soup.body.contents))print(soup.body.contents[0])
结果如下:
This is a python demo page [This is a python demo page ]['\n',The demo python introduces several python courses.
, '\n',Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:Basic Python and Advanced Python.
, '\n']5
标签树的下行遍历:
for child in soup.body.children: print(child) # 遍历儿子节点
for child in soup.body.descendants: print(child) # 遍历子孙节点
b.标签树的上行遍历

import requestsfrom bs4 import BeautifulSoupurl = 'http://python123.io/ws/demo.html'demo = requests.get(url)soup = BeautifulSoup(demo.text, 'html.parser')print(soup.title.parent)print(soup.title.parents)print(soup.html)print(soup.html.parent) # 和上面一样的print(soup.parent) # 空
结果如下所示:
This is a python demo page This is a python demo page The demo python introduces several python courses.
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:Basic Python and Advanced Python.
This is a python demo page The demo python introduces several python courses.
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:Basic Python and Advanced Python.
None
典型标签树的上行遍历代码如下所示:
import requestsfrom bs4 import BeautifulSoupurl = 'http://python123.io/ws/demo.html'demo = requests.get(url)soup = BeautifulSoup(demo.text, 'html.parser')for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name)
结果如下所示:
pbodyhtml[document]
遍历所有先辈节点,包括soup本身,所以要区别判断
c.标签树的平行遍历

 平行遍历代码如下:
平行遍历代码如下: import requestsfrom bs4 import BeautifulSoupurl = 'http://python123.io/ws/demo.html'demo = requests.get(url)soup = BeautifulSoup(demo.text, 'html.parser')print(soup.prettify())print(soup.a.next_sibling.next_sibling)print(soup.a.previous_sibling.previous_sibling)print(soup.a.next_sibling)print(soup.a.previous_sibling)print(soup.a.parent)
结果如下:
This is a python demo page The demo python introduces several python courses.
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: Basic Python and Advanced Python .
Advanced PythonNone and Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:Basic Python and Advanced Python.
标签树的平行遍历:
for sibling in soup.a.next_sibling: print(sibling) # 遍历后续节点
for sibling in soup.a.previous_sibling: print(sibling) # 遍历前续节点
(4)基于bs4库的HTML格式输出
a.bs4库的prettify()方法
让HTML内容更加“友好”的显示——bs4库的prettify()方法
- prettify()为HTML文本<>及其内容增加更加’\n’
- .prettify()可用于标签,方法:<tag>.prettify()
b.bs4库的编码
bs4库将任何HTML输入都变成utf‐8编码 Python 3.x默认支持编码是utf‐8,解析无障碍
2、信息标记与提取方法
(1)信息标记的三种形式
- 一个信息——‘北京理工大学’
- 一组信息——‘北京市海淀区中关村’ ‘首批985高校’‘中国共产党创办的第一所理工科大学’‘首批211高校’‘工业和信息化部’1940’第一辆轻型坦克’……
- 信息的标记——‘name’,‘北京理工大学’ ‘addr’,‘北京市海淀区中关村’
为什么要标记?
- 标记后的信息可形成信息组织结构,增加了信息维度 ;
- 标记的结构与信息一样具有重要价值
- 标记后的信息可用于通信、存储或展示
- 标记后的信息更利于程序理解和运用
HTML的信息标记包括——文本 声音 图像 视频,其中声音 图像 视频称为超文本,HTML是WWW(World Wide Web)的信息组织方式
HTML通过预定义的<>…</>标签形式组织不同类型的信息
信息标记有哪些种类呢?
- XML(eXtensibleMarkup Language)
- JSON(JavsScript Object Notation)
- YAML(YAML Ain’tMarkup Language)
a.XML
可扩展标记语言


…
b.JSON



“key” :“value” “key” :[“value1”,“value2”] “key” : {“subkey” :“subvalue”} C.YAML

 表达并列关系:
表达并列关系:  | 表达整块数据 # 表示注释
| 表达整块数据 # 表示注释 
key :value key :#Comment ‐value1 ‐value2 key : subkey:subvalue
(2)三种信息标记形式的比较
XML实例:
Tian Song 中关村南大街5号 北京市 100081 Computer System Security
JSON实例:
{“firstName” :“Tian”, “lastName” :“Song”, “address” : { “streetAddr” :“中关村南大街5号”, “city” :“北京市”, “zipcode” :“100081” } , “prof” :[“Computer System” ,“Security” ]} YAML实例:
firstName:Tian lastName:Song address : streetAddr:中关村南大街5号 city :北京市 zipcode:100081 prof : ‐Computer System ‐Security
可以发现:
| XML | 最早的通用信息标记语言,可扩展性好,但繁琐,Internet上的信息交互与传递 |
|---|---|
| JSON | 信息有类型,适合程序处理(js),较XML简洁,移动应用云端和节点的信息通信,无注释 |
| YAML | 信息无类型,文本信息比例最高,可读性好,各类系统的配置文件,有注释易读 |
(3)信息提取的一般方法
信息提取:从标记后的信息中提取所关注的内容(标记, 信息),XML JSON YAML
- 法I:完整解析信息的标记形式,再提取关键信息 需要标记解析器,例如:bs4库的标签树遍历。 优点:信息解析准确 缺点:提取过程繁琐,速度慢
- 法II:无视标记形式,直接搜索关键信息 。对信息的文本查找函数即可 优点:提取过程简洁,速度较快 缺点:提取结果准确性与信息内容相关
- 结合形式解析与搜索方法,提取关键信息。需要标记解析器及文本查找函数
实例:提取HTML中所有URL链接
思路:1) 搜索到所有以下标签2)解析标签格式,提取href后的链接内容
from bs4 import BeautifulSoupimport requestsurl = 'http://python123.io/ws/demo.html'r = requests.get(url,timeout=30)demo = r.textsoup = BeautifulSoup(demo,'html.parser')for link in soup.find_all('a'): print(link.get('href')) 结果如下所示:
http://www.icourse163.org/course/BIT-268001http://www.icourse163.org/course/BIT-1001870001
(4)基于bs4库的HTML内容查找方法
<>.find_all(name,attrs,recursive, string, **kwargs)
返回一个列表类型,存储查找的结果
- name 对标签名称的检索字符串
from bs4 import BeautifulSoupimport requestsurl = 'http://python123.io/ws/demo.html'r = requests.get(url,timeout=30)demo = r.textsoup = BeautifulSoup(demo,'html.parser')print(soup.find_all('a'))print(soup.find_all(['a','b'])) 结果如下所示:
[Basic Python, Advanced Python][The demo python introduces several python courses., Basic Python, Advanced Python]

- attrs 对标签属性值的检索字符串,可标注属性检索

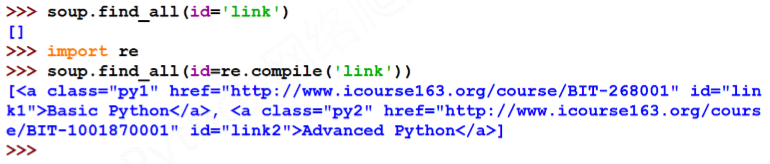
- recursive 是否对子孙全部检索,默认True

- string <>…</>中字符串区域的检索字符串

(..) 等价于 .find_all(..) soup(..) 等价于 soup.find_all(..)
扩展方法

转载地址:http://bgvrn.baihongyu.com/